句向量SDK【支持100种语言】
句向量是指将语句映射至固定维度的实数向量。 将不定长的句子用定长的向量表示,为NLP下游任务提供服务。
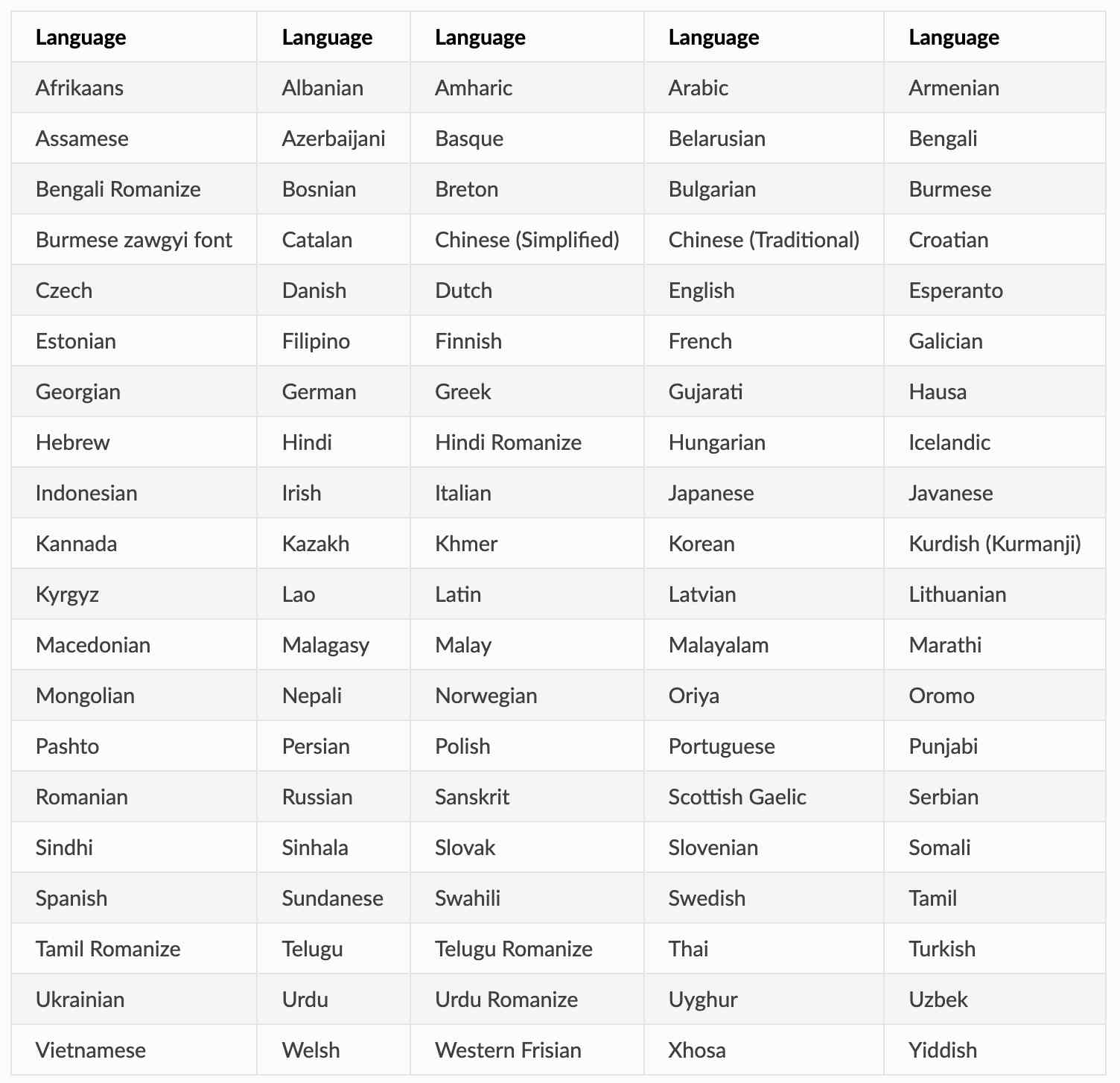
- 支持下面100种语言:
- 句向量
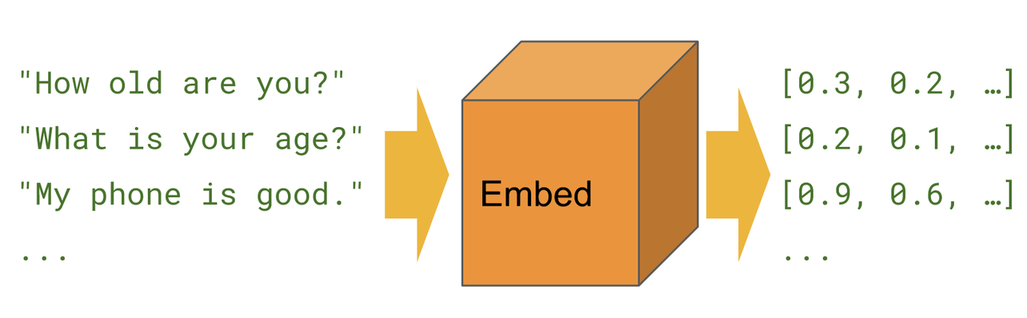
句向量应用:
- 语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器
SDK功能:
- 句向量提取
- 相似度(余弦)计算
- max_seq_length: 128(subword切词,如果是英文句子,上限平均大约60个单词)
运行例子 - SentenceEncoderExample
运行成功后,命令行应该看到下面的信息:
...# 测试语句:# 英文一组[INFO ] - input Sentence1: This model generates embeddings for input sentence[INFO ] - input Sentence2: This model generates embeddings
# 中文一组[INFO ] - input Sentence3: 今天天气不错[INFO ] - input Sentence4: 今天风和日丽
# 向量维度:[INFO ] - Vector dimensions: 768
# 英文 - 生成向量:[INFO ] - Sentence1 embeddings: [0.10717804, 0.0023716218, ..., -0.087652676, 0.5144994][INFO ] - Sentence2 embeddings: [0.06960095, 0.09246655, ..., -0.06324193, 0.2669841]
#计算英文相似度:[INFO ] - 英文 Similarity: 0.84808713
# 中文 - 生成向量:[INFO ] - Sentence1 embeddings: [0.19896796, 0.46568888,..., 0.09489663, 0.19511698][INFO ] - Sentence2 embeddings: [0.1639189, 0.43350196, ..., -0.025053274, -0.121924624]
#计算中文相似度:#由于使用了sentencepiece切词器,中文切词更准确,比15种语言的模型(只切成字,没有考虑词)精度更好。[INFO ] - 中文 Similarity: 0.67201